
🤖 Reinforcement Learning for VLA
My research in embodied AI focuses on developing efficient reinforcement learning frameworks for training and fine-tuning Vision-Language-Action (VLA) models, enabling robots to learn complex manipulation tasks.
First-Author Papers
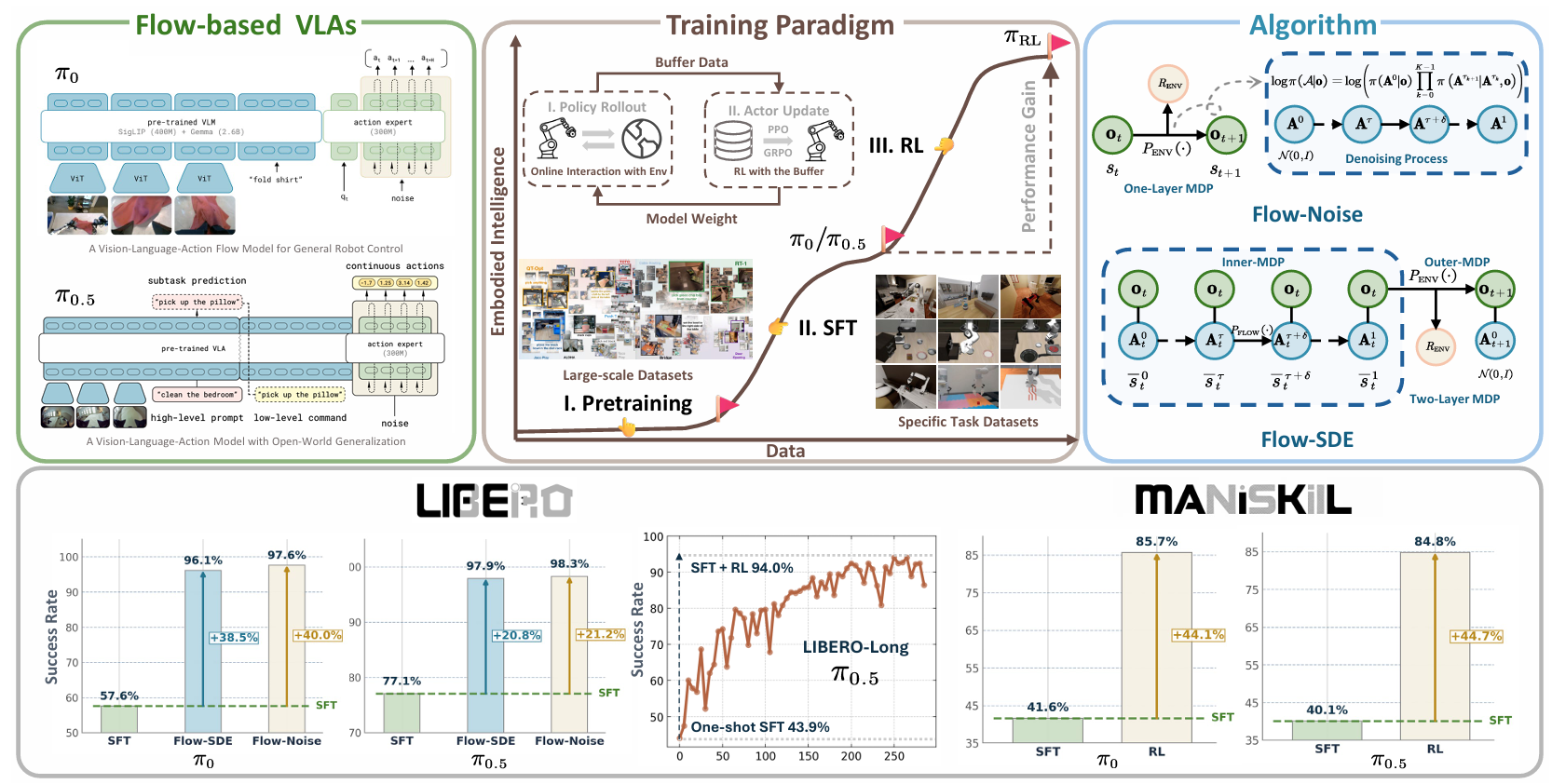
### πRL: Online RL Fine-tuning for Flow-based Vision-Language-Action Models
**arXiv 2024**
We introduce the first open-source framework for efficient RL fine-tuning with flow-based VLA models. The framework achieves 40%+ improvement over behavior cloning on manipulation tasks with successful sim-to-real transfer.
**Key Contributions:**
- First open-source RL fine-tuning framework for flow-based VLAs
- Scalable training infrastructure for large VLA models
- Novel policy gradient methods for flow-matching architectures
\[[Paper](https://arxiv.org/abs/2510.25889)\] \[[Code](https://github.com/RLinf/RLinf)\]
Research Vision
The intersection of large language models and robotics is rapidly evolving. My research aims to:
- Democratize Robot Learning: Make RL fine-tuning accessible without massive compute
- Bridge Sim-to-Real: Develop methods that transfer effectively to real robots
- Enable Generalization: Train robots that adapt to new tasks with minimal data